leanaiproblem-solving
Humans Are End-to-End, LLMs Are Middle-to-Middle
The Perplexing Reality
Lately I’ve been reflecting on the perplexing reality of AI — specifically, large language models (LLMs). After months of working side-by-side with these systems and using them to draft articles, build complex software, and even create coaching apps, this quote below is what strikes me most about the current situation:
Humans are end-to-end. LLMs are middle-to-middle.
That simple phrase captures both the power and the limitation of today’s technology. It also reflects something very human — our urge to step back and make sense of what we are building. Researchers are already working to give the next generation of models a more continuous learning ability, connecting vision, action, and feedback. But we are not there yet. For now, understanding this divide helps us work more intelligently with the tools we have.
The phrase “middle-to-middle” was popularized by technologist Balaji Srinivasan, who briefly mentioned it in several articles and podcasts including an episode at the channel a16z on YouTube: “How AI Will Change Politics, War, and Money.” He noted that current AI systems don’t yet operate end-to-end — they still require a human to begin (prompt) and another to finish (verify). This shifts both the cost and the cognitive effort to the edges of the process where humans still excel.
How Ai Will Change Politics, War, and Money
That framing made me reflect on parallels I was seeing within Lean thinking and problem solving, where humans already manage the ends and middle of the Plan Do Check Act (PDCA) management loop: defining purpose, identifying direction, and verifying outcomes. But I often find that many humans are also relatively weak in the middle at reasoning and causal analysis factors. I wanted to expand on this idea and apply it to the Lean and problem-solving domain — showing how humans and LLMs can learn together by connecting the ends and the middle. I have previously used the phrase Humans + Ai > Problems to describe this phenomenon.
Humans as End-to-End Learners
Human learning runs the full gamut from perception to action to reflection.
We see, judge, decide, act, and learn. We have eyes and ears and we are always in state of monitoring the external world around us.
In other words our feedback comes from the real world — the tone of a machine, the look on a customer’s face, the feeling that something just isn’t right.
We connect experiences to consequences.
In Lean thinking terms, we live the fullest version of the PDCA cycle.
ℹ️What is PDCA
Plan-Do-Check-Act is a foundational Lean methodology for continuous improvement. It's a cyclical process where you plan a change, execute it, check the results, and act on what you learned.
We plan based on what we see, find a problem or opportunity, do something about it, check results, and adjust.
That continuous loop — grounded in experience and meaning — makes us effective end-to-end learners.
We close the loop because we live inside it.
LLMs as Middle-to-Middle Reasoners
AI and specifically LLMs, by contrast, inhabit the symbolic middle of cognition.
They don’t perceive the world directly or act within it; they operate inside the realm of language (tokens), code, and representation.
Currently their loop runs from prompt → token reasoning → text output. I am putting aside the diffusion models and image generation, but it is still fundamentally the same pattern.
Within that symbolic space, they are astonishingly capable at certain tasks — connecting ideas, reframing problems, referencing examples and synthesizing knowledge at extraordinary speed.
But they are not learning from experience in real time.
The models reason statistically, not situationally.
The models work within human language, not alongside daily human life. You must turn them on and provide context to get started. Then they mostly forget unless you manage them with some form of augmentation session to session. This area of on-line continuous real time reinforcement learning is a hot topic of research.
The Reality of Jagged Performance
This contrast explains why reactions to AI are often so polarized: some people stand atop those towers, sky-high on their potential, while others wander the alleyways below, quick to dismiss their flaws as 'AI slop.' Both views are true to the experience — they’re just seeing different parts of the same uneven landscape.
Yet when I ask them to define the real purpose behind a project or to judge whether a proposed solution truly worked in practice, the initial results often miss the mark. Without extensive context, they can’t perceive the situation as we do — they don’t hear the tone of the machine, see the customer’s expression, or walk the floor after a change. These are the human “ends” of the loop — perception and verification — where models remain weak.
Once I provide the right inputs, data, and standards, however, the models perform extraordinarily well in the middle — connecting ideas, structuring reasoning, and accelerating synthesis. In other words, I “Prompt”, the models “Do”, we both “Check”, and then I “Act” and adjust again — a new digital derivative of PDCA for cognitive work.
Loops vs. Layers
Together they become stronger — a true case of humans and AI combining to solve problems neither could alone.
When we confuse loops for layers, we either expect too much (“it should know better”) or too little (“it’s just autocomplete”). The truth sits between: humans span the full loop; LLMs inhabit the middle.
Humans learn through experiential learning loops — sensing, acting, and adjusting based on feedback over time. LLMs operate through layers — statistical patterns that transform language into more language. One learns from the world; the other models it.
Learning to Work Together
The real opportunity is not competition but coordination.
The key question is no longer who’s smarter but how do we learn together?
Humans bring:
- Purpose, context, and judgment.
- The ability to see reality, recognize opportunities, define standards, and recognize meaningful change.
LLMs bring:
- Scale, memory, speed, and pattern integration.
- The models give us the ability to organize information, generate ideas, and accelerate reasoning.
Together, they form a two-layer PDCA loop — one experiential, one linguistic — that augments learning rather than replaces it.
The Two-Layer PDCA Loop
Think of a standard PDCA cycle with two horizontal layers working in harmony:
| PDCA Step | Human Role (End to End) | LLM Role (Middle to Middle) |
|---|---|---|
| P-Plan | Perceive the situation, define purpose, decide direction, and set hypotheses. | Structure the plan, summarize facts and standards, draft problem statements, propose analysis frameworks. |
| D-Do | Execute countermeasures, observe real results, coordinate people and actions. | Generate checklists, simulate scenarios, document actions, visualize expected outcomes. |
| C-Check | Compare actual results against expectations, interpret variation, and reflect on learning. | Analyze data, generate before/after comparisons, highlight anomalies or trends, synthesize lessons. |
| A-Act | Decide next steps, standardize successes, share learning, and set new challenges. | Update documentation, create training materials, and propose next-iteration improvements. |
You can also view this as a variant of PDCA for digital work. In a simplified version it becomes Prompt-Do-Check-Act. Either way this is PDCA amplified — not redefined.
The human layer grounds learning in reality of the start and the ends; the LLM layer accelerates structure, analysis, calculation, synthesis, in the middle.
The loop becomes faster, richer, and more deliberate.
“Humans start and close the loop; LLMs clarify the middle.
Together, they shorten the distance between thinking and learning.” Humans + Ai > Problems.
The Next Frontier
Researchers are already exploring how to connect future models more tightly to human level perception, advanced tools, memory, and types of feedback. But I personally think this is still quite a ways in the future.
When that happens, the boundary between “end-to-end” and “middle-to-middle” will blur.
But even then, someone must still define purpose, verify outcomes, and decide what good looks like.
That remains a human responsibility — and a human privilege.
Closing Reflection
For now, we live in a world of collaboration — humans who can see and act end-to-end, and models that reason brilliantly but incompletely in the middle. Our task is not to collapse that difference but to connect it.
"Humans are end-to-end. LLMs are middle-to-middle."
That distinction defines how learning happens today — through two complementary systems, one grounded in experience, the other in language. The value lies in joining these worlds into one continuous learning system.
In Lean, improvement depends on closing the loop and learning. In the age of language models, so does intelligence. Our future will depend not on which side learns faster, but on how well we close the loop together.

About Art Smalley
Art Smalley is a leadership and Lean management expert with nearly 40 years of experience in operations and continuous improvement. He worked at Toyota and McKinsey & Company. He is a senior advisor to the Lean Enterprise Institute, author of four books, and has helped organizations worldwide implement sustainable improvement practices.
Related Articles
leantoyota
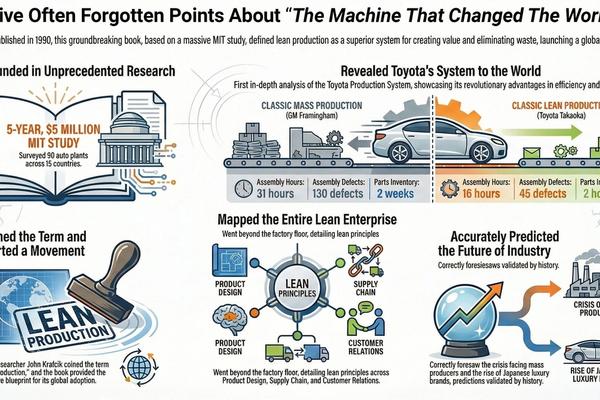
Reflecting On Machine That Changed The World - 35 Years Later
The Machine That Changed the World remains, 35 years later, the most comprehensive and empirically grounded explanation of Toyota as a complete enterprise system—not a collection of factory tools. Built on unmatched MIT research, the book quantified a structural performance gap between lean and mass production across product development, manufacturing, supply chains, and management, launching the Lean movement and defining its core vocabulary. Despite decades of Lean activity since, no later work has equaled its enterprise-wide scope, comparative rigor, or lasting explanatory power

problem-solvingleadership-management
The Coffee House Delusion - Why "Liquid Networks" Are Overrated
For years we’ve been told innovation comes from “creative collisions” — open offices, hallway chats, coffeehouse serendipity. But the evidence suggests that’s mostly a myth. Real breakthroughs are usually born in deep solitude, refined through structured review, and only then spread through networks.

leantoyota
Which Supermarket: Reviewing the Origins of Toyota's Pull System
An amusing internet tale about Toyota often goes something like this: the company’s legendary pull system sprang from Taiichi Ohno's epiphany during a visit to a Memphis-based supermarket chain called Piggly Wiggly. According to the legend, Ohno visited the store during a 1956 U.S. visit and was amazed by the way shelves were instantly refilled as customers shopped. And the thus the concept for his replenishment “supermarket” style of production was born. Despite the fact that no one can seem to locate a primary source for this story, it has been widely repeated for decades on internet blogs, LinkedIn, Wikipedia, and even by major news outlets like Reuters.